
tl;dr
- reduce ...spread belongs to a different complexity class than the optimal solutions, which is bad
- javascript engines will probably never optimize this code
- if you're using reduce ...spread for reasons of immutability, you should copy once or use immutable helper libraries
Performance is a common topic in computing, but it is especially common in the frontend world as the latest Javascript technologies battle for the frontend throne. Some may say React has already won (and the usage numbers seem to agree) so in this blog post I wanted to talk about a piece of problematic code I’m seeing more frequently in the frontend world as Javascript syntax is evolving and components are taking over.
You’ve probably been in a situation where you wanted to merge an array of object maps into a singular object. Here’s two common solutions to the problem.
let items = [
{name: "something", value: true},
// ...
];
// use reduce to build the new map into an accumulator
// we'll refer to this as "reduce mutate"
let result = items.reduce((acc, item) => {
acc[item.name] = item.value;
return acc;
}, {});
// equivalent as as a for loop
let result = {};
for(let item of items) {
result[item.name] = item.value;
}While the later “for loop” is arguably easier to read, the former “reduce” is fine and becoming more common as the React community increasingly adopts a more functional programming style, often eschewing iterative statements in favor of function expressions which can be easily inlined into components. I personally like them both.
I’m not so much a fan of this latest emerging style.
// we'll call this "reduce ...spread"
let result = items.reduce((acc, item) => ({
...acc, [item.name]: item.value
}), {})For those unfamiliar with
spread syntax (...) in object literals,
it behaves very similarly to
Object.assign in that
you can use it for iterating over a source object’s properties to copy them into a target object. In this case we’re
copying to a newly created object. Can you see the problem? I’m not referring to the object initialization, that’s only
slightly problematic.
One functional downside: hidden iteration. Seems some coders would balk at for;for;for; but have no qualms with .map.filter.reduce.
— Rich Snapp (@snapwich) October 20, 2016
Hidden iteration! When Array#Map and the crew were newer it wasn’t uncommon to see coders using them excessively,
(often sequentially and multiple times over the same data set). Now with the spread operator in its honeymoon phase
developers are back to experimenting with new and exciting programming patterns; some good (... is great with
configuration objects), and some bad. Unfortunately the magic nature of the spread operator has been somewhat
troublesome when it comes to reviewing code that includes reduce...spread. Convincing people to avoid that pattern
because of the nested looping is often met with “what loops?”, “premature optimization!”, or “that’s mutation!” So below
we’re going take a quick dive into engine internals to find the missing loops, talk a bit about optimization and
computational complexity, and finally will talk a bit about functional programming.
A quick dive into a Javascript engine
When Javascript code is encountered in something like a browser, the execution of that code is handled by a Javascript engine. Several engines exist, but we’re going to specifically talk about Chrome and Node’s default engine: v8. How the v8 engine works is a complex topic, but the basics are covered in this excellent presentation.
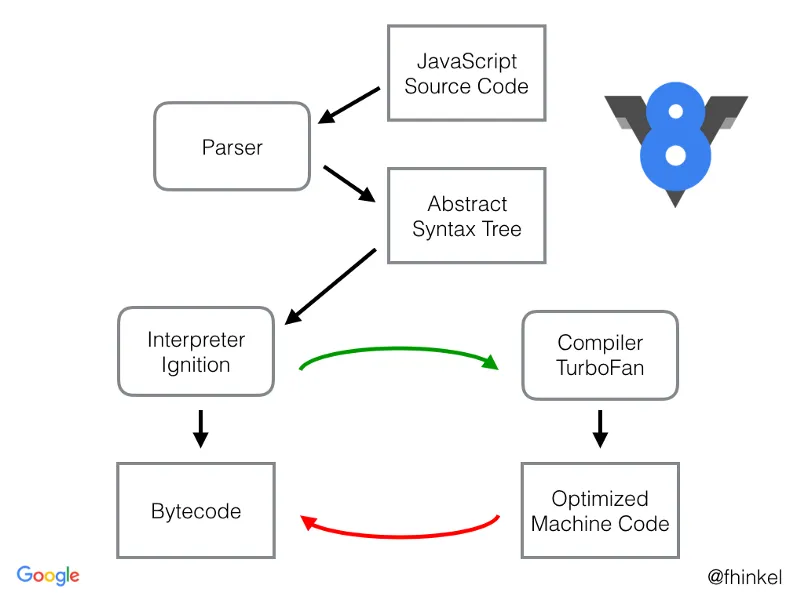
V8’s compiler pipeline - credit to @fhinkel
Currently, there are three components that constitute the compilation layers performed by the v8 engine: the parser, which generates an abstract syntax tree (AST); an interpreter, which generates bytecode; and an optimized compiler, which generates machine code.
All of this is performed at run time (rather than during a separate compilation step) in a process known as just-in-time (JIT) compilation.
By looking at the bytecode generated by v8’s interpreter, Ignition, we can get a more accurate picture of what our Javascript code will actually be doing.
The following bytecode is generated from reduce ...spread with the important bits highlighted.
// bytecode
StackCheck
CreateObjectLiteral [0], [0], #41, r0
Mov r0, r1
Mov a0, r2
<mark>CallRuntime [CopyDataProperties], r1-r2</mark>
LdaNamedProperty a1, [1], [1]
ToName r1
LdaNamedProperty a1, [2], [3]
StaDataPropertyInLiteral r0, r1, #0, [5]
Ldar r0
Return// builtin code generation
SetOrCopyDataProperties( /* ... */ ) {
// ...
ForEachEnumerableOwnProperty
(
context, source_map, CAST(source), kEnumerationOrder,
[=](TNode<Name> key, TNode<Object> value) {
CallBuiltin(Builtins::kSetPropertyInLiteral, context, target, key, value);
},
if_runtime);
// ...
}The bytecode will generate code that makes a runtime call which maps to an inlined builtin generated with the loop we were looking for. I guess we were performing nested iteration after all…
Determining our computational complexity
Discussing the complexity of a piece of code requires an understanding on the amount of resources that said code will
use when ran. Specifically, when comparing our reduce mutate solution to reduce ...spread, we’ll be talking about
their respective time complexities; in other words, how long each
solution takes to run given a certain input size. These time approximations are usually denoted in
Big 𝑂 notation, for example: 𝑂(1) for
constant time or 𝑂(n) for
linear time.
Figuring out the time complexity of code that iterates over a set of data (in our case, with reduce) of size n
involves finding the constant time operation we’re concerned about in our solution and determining how many times that
operation will be executed. For us, the base operation we’re interested in is the insertion of data into our objects,
which in general is a constant time operation. We can see
this represented in one solution as Javascript with acc[item.name] = item.value; and in the other solution with the
machine code generated by Builtins::kSetPropertyInLiteral. The fact that these code paths likely have different
implementations isn’t important, only that they’re both constant time.
We can see in reduce mutate that our base operation is only happening once for each iteration of reduce; in other
words, it’s happening n times for an input array of size n so we can classify it as linear time: 𝑂(n). However, with
reduce...spread it’s actually performing a few other operations, specifically the creation of a new object literal and
then again iterating (nested iteration in this case, since it’s inside our previous iteration) over the existing
property keys and then performing our base operation for each nested iteration. How many times is our base operation
happening then? Well, it’s complicated. It doesn’t exactly execute the inner loop n times since the inner loop is
limited by the amount of keys it needs to copy. However, for our purposes it’s good enough to say it’s in the same
class of solutions that execute n * n or
n2 times and call it 𝑂(n2) since it trends that way anyways as n goes towards infinity, but for
a more accurate description we could notate it as
𝜃(𝑛2) ≡ 𝑂(𝑛2) 𝑎𝑛𝑑 Ω(𝑛2).
Note: The above assumes no duplicate keys are generated in your target object. For most example I’ve
seen of mapping an array of objects to object key->values that holds true and I think is a fair assumption. However,
there are situations where that’s obviously not true, like with a solution specifically meant for
counting duplicates (think word count). In those situations using the reduce…spread
pattern would still be classified as 𝑂(𝑛2) (as big O notation is an approximation of the upper bound) but
actual run times would probably be more accurately reflected by also considering best-case (all duplicates) and
average-case complexity as well.
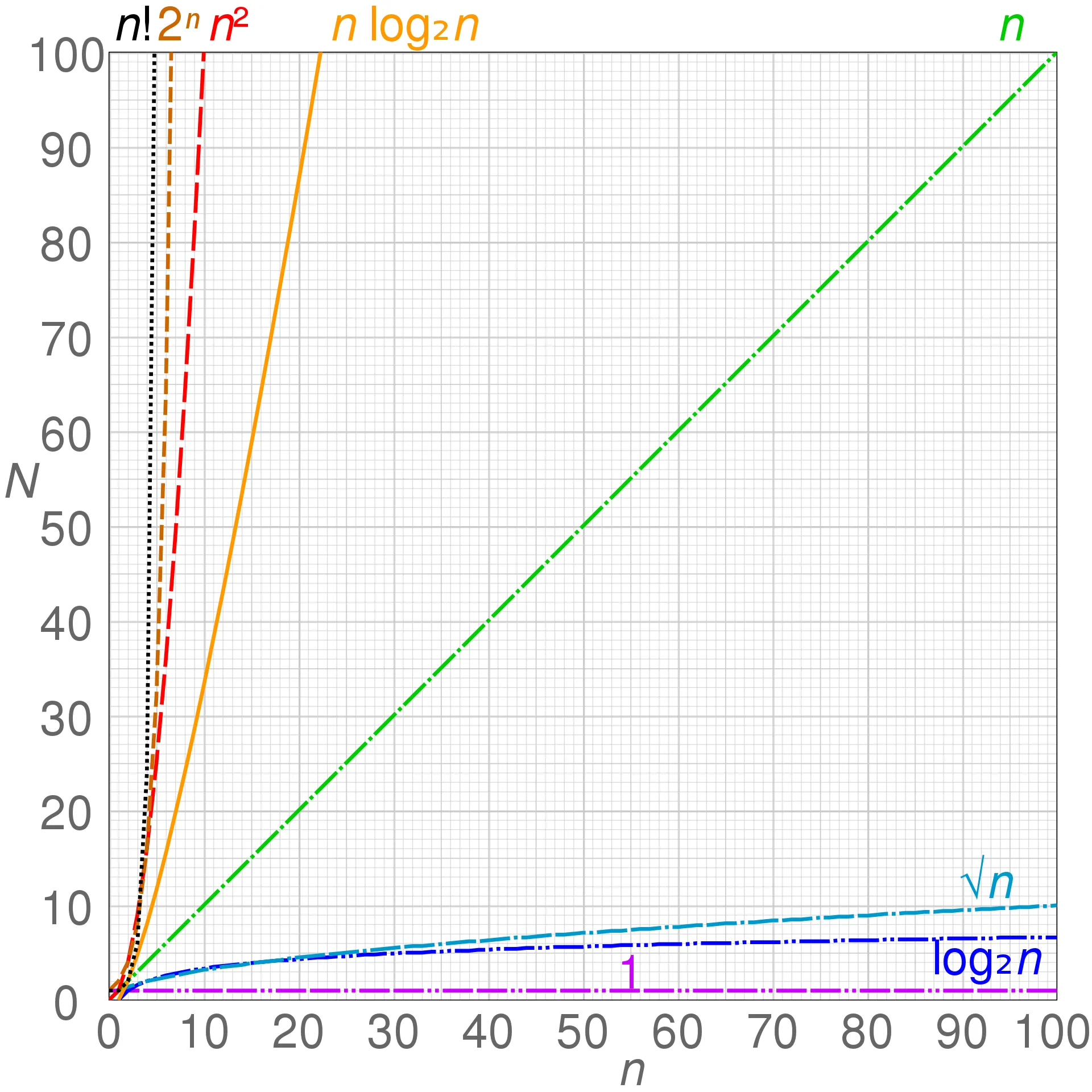
credit to Cmglee - Own work, CC BY-SA 4.0
We can see on the provided diagram how different classifications of algorithms perform for different input sizes. The class groupings represent comparable runtime characteristics for different algorithms, i.e. two different algorithms that are 𝑂(n) may have different execution times, but their run time will grow comparably to each other as the input size they operate on grows. Understanding how code will generally perform helps to write appropriate solutions to the problems we are trying to solve and help us know certain performance characteristics of the code without even running it!
Okay, so one of our solutions is 𝑂(n) and the other is 𝑂(n2)… big whoop! Is that really so bad? Isn’t worrying about this just a case of premature optimization? Won’t the optimizing compiler save us anyways? Well, looking at our informative diagram seems to demonstrate that 𝑂(n) and 𝑂(n2) have very different performance characteristics. Let’s see how they pan out in actual benchmarks.
I’ve included our two discussed solutions reduce mutate and reduce...spread in these tests as well as some
additional benchmarks including the for..of, referenced above, and some solutions using immutable data structures for
our later talk on functional programming. You can
see the code that was used to run these benchmarks here.
One thing immediately noticeable is how much faster reduce mutate and for..of are than the competition when it comes
to a small amount of items. Why that is, I’m not quite sure; I thought it might have something to do with the optimizer
but I was unable to normalize the spikes with benchmark warmups (to ensure JIT optimizations in all our results) or by
limiting test cycles.
That’s not super important though as we’re here to see what different time complexities means for our code; the real
problem can be seen when we click reduce...spread 𝑂(n^2) on the chart above and adjust the data so we can see how it
compares to the other solutions over time. Then we can click on reduce mutate 𝑂(n) and see how it compares. Did you
see the difference? If we compare any of the 𝑂(n) solutions to the others, we’ll see that they basically perform at some
consistent time multiple of the other 𝑂(n) solutions. Example: clicking for..of 𝑂(n) will show that
reduce mutate 𝑂(n) is 3/4 the speed, but it’s pretty much always 3/4 the speed no matter the size of our data set.
However, if we click reduce...spread 𝑂(n^2) and compare it to reduce mutate 𝑂(n), first it’s 20 times slower, then
40, then 80. It’s growing steadily slower! That’s bad news.
anti-pattern: common response to a recurring problem that is usually ineffective and risks being highly counterproductive.
The reason I consider reduce...spread an anti-pattern is because of its growing popularity combined with its
non-obvious performance issue; non-obvious because most would expect directly mapping an array of objects to a similar
number of object properties to require a linear amount of work: 10 items will take ~10ms, 20 items will take ~20ms, etc.
However, that is not the case. This thing will kill your application’s performance quickly if you follow such a sane
assumption.
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
Most of us have heard part of that quote, but usually not the whole thing. There is such thing as premature
optimization, however this is not one. If anything, I’d suggest that reduce...spread is a premature de-optimization.
Premature optimizations are things such as choosing to use the fastest 𝑂(n) solution provided in my benchmarks over the
other 𝑂(n) solutions because it is the fastest. Which 𝑂(n) solution you choose is probably inconsequential from a
performance standpoint; it’s entirely possible that you’d see different results in different Javascript engines and that
advancements in v8’s optimizing compiler could change these results tomorrow.
Could the same be said for reduce...spread and its 𝑂(n2) time? Probably not. Here’s a relevant point on
optimizing compilers (emphasis added):
Optimizing compilers focus on relatively shallow constant-factor performance improvements and do not typically improve the algorithmic complexity of a solution. For example, a compiler will not change an implementation of bubble sort to use mergesort instead.
Now that’s not saying it can’t be optimized; obviously it can, because we did it by utilizing mutation. But looking at our benchmarks it’s obvious that it is not currently optimized and it’s unlikely it ever will be. You can see a few discussions around this exact pattern on this tweet asking for potential optimizations to spreading inside object literals, if you’re interested.
Functional purity
Finally, let’s talk a bit about functional programming. The final argument I hear in favor of reduce...spread is for
reasons of functional purity, in that our reduce function is mutating one
of its parameters (the accumulator), and that’s bad. But what potential bugs are we preventing by avoiding mutation in
this case?
Let’s look at the code again, this time highlighting an important part.
let result = items.reduce((acc, item) => ({
...acc, [item.name]: item.value
}), {}) // notice object literal for initializationThe object we’re avoiding mutation on is a reference that we created; in other words, mutating this parameter is not dangerous and worrying about mutating it is in-fact a case of premature de-optimization.
Is your linter complaining? If so, that’s exactly why linters give us the ability to ignore certain lines. Linters are useful in alerting us to potential trade-offs, but in this case (with our new found wisdom) we can decide to ignore it and avoid a potential pitfall. You could also use the for loop instead and avoid reduce (and linting errors) altogether.
If you would like to generalize the reduce mutate code to work in situations where you may be working with data that
doesn’t belong to you, I suggest either making a copy of that data before iterating or using immutable data structures
(as that is what they are created for).
In the benchmarks I’ve included some examples of
using immutable.js with and without mutations (that’s right, an
immutable library provides helpers for mutating data) and immer.js. Immutable data
structures provide the benefit of allowing destructive operations without modifying the original source object you are
operating on. They also do this with the added benefit of sharing the underlying data to prevent waste like in
reduce...spread. If you want to code with immutability in mind then I suggest using the right tools for the job. You
also might be interested in
this proposal of a const value type.
In conclusion
Please avoid this pattern in your code! If you are reviewing code that contains this pattern, feel free to reference this blog post.